CHAI: Chat + AI
Quant traders building AI Platform
Palo Alto, CA
[ Daily Active Users Growth ]
Incentives & Scale
RESEARCHAll platforms work best with the right incentives. At CHAI, we've tried paying developers, but the biggest motivators remain high-quality feedback, recognition, and the satisfaction of building a popular LLM. Our scale enables the critical mass of feedback and models needed to create strong feedback loops.


[ Product ]
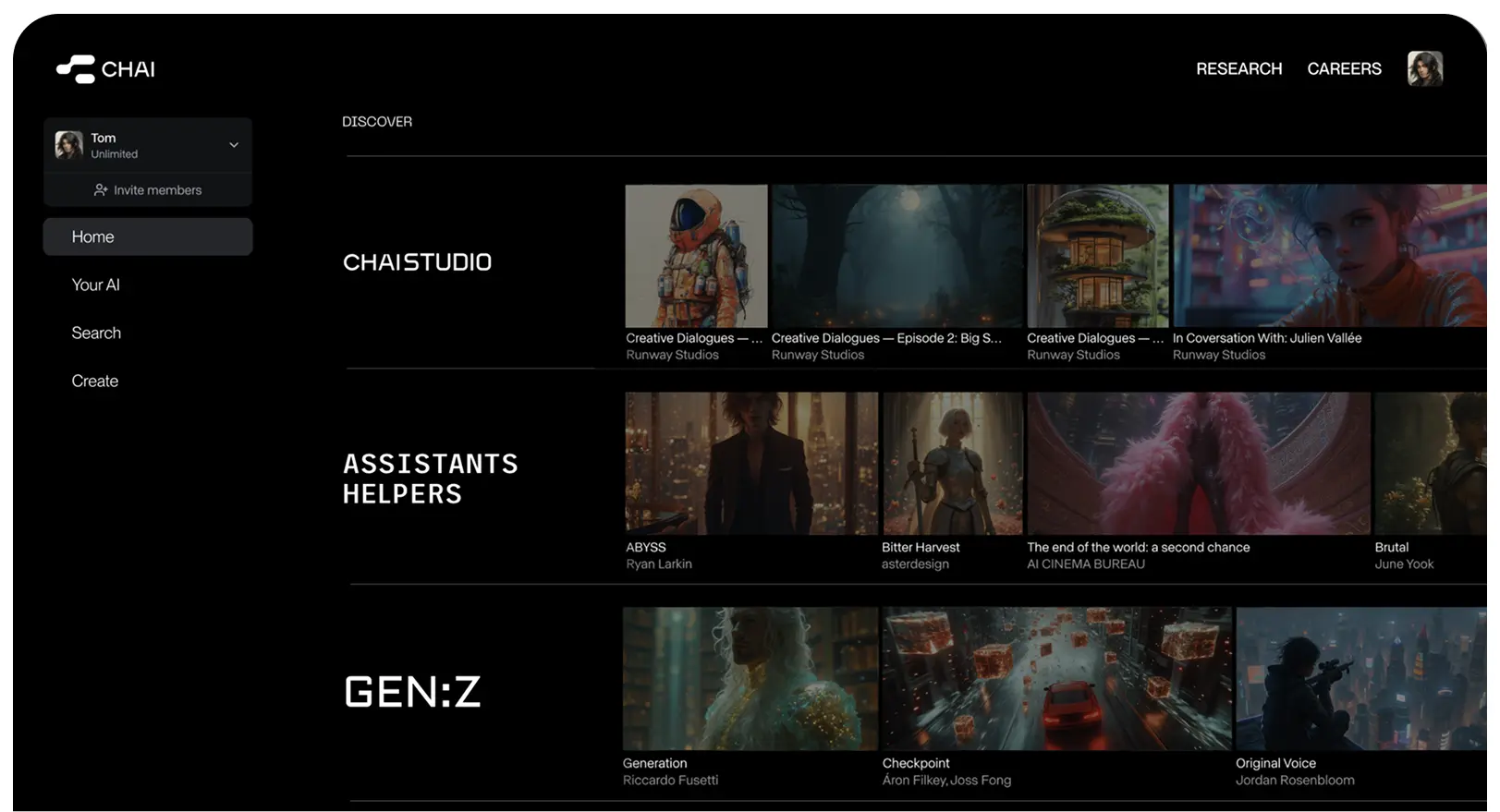
Building Platform for Social AI
We believe in platforms. There is huge demand for AI that is not only factually correct but also entertaining and social.

1.4 EXAFLOPS GPU CLUSTER
FOR AI INFERENCE
CLUSTER
At CHAI, we serve hundreds of in-house trained LLMs across several GPU chip types from both AMD and Nvidia. While open-source solutions such as vLLM work well for simple workloads, we've found that we can further improve upon vLLM by almost an order of magnitude through several optimizations, such as custom kernels and compute-efficient attention approximations.



